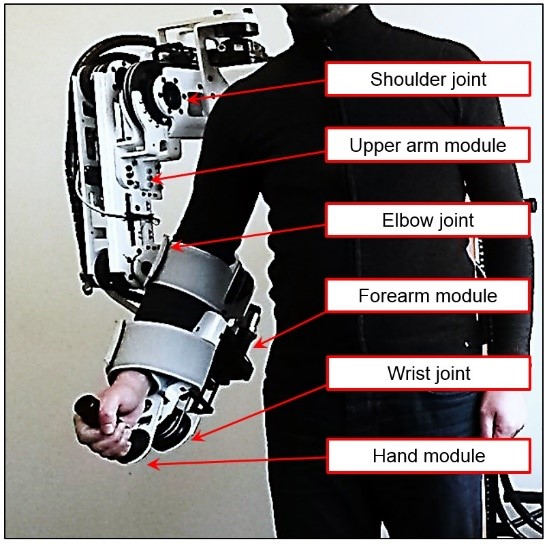
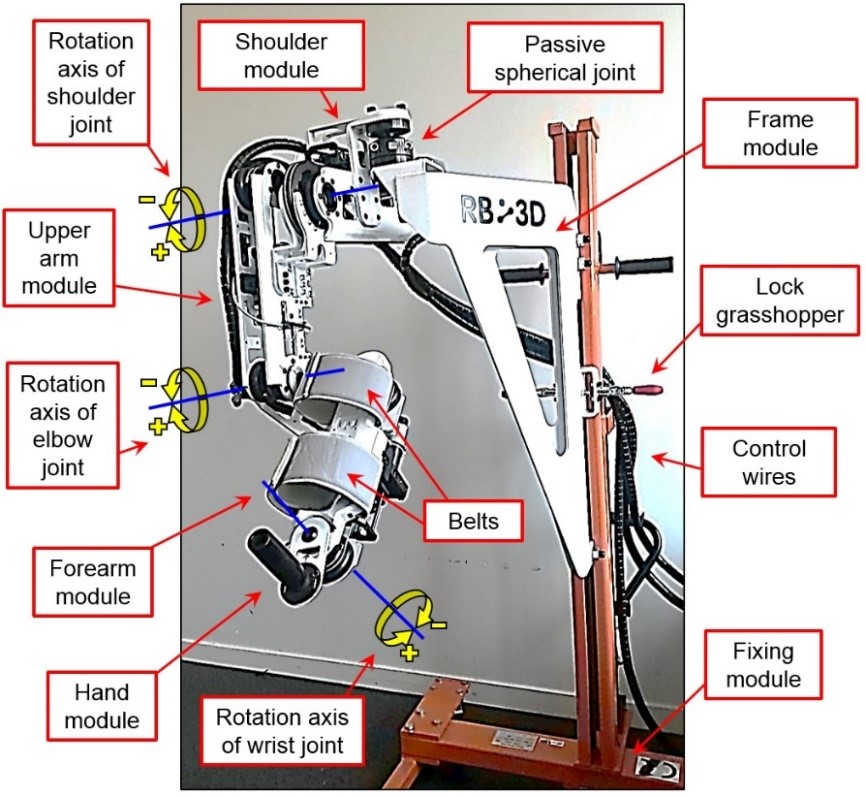
ULEL is a unique exoskeleton prototype developed by RB3D company especially for the LISSI laboratory. This exoskeleton is designed to perform scientific research on the rehabilitation of the human right arm (see Figure 1.1). It is constituted by the following six modules: The first one (Fixing module) can lift the exoskeleton at the desired level using a hydraulic system. The second module (Frame module) is connected to the first one by a vertical prismatic joint. The third module (Shoulder module) is connected to the previous module by a passive spherical joint. The last connection is used for the 3-D orientation of the exoskeleton. The fourth module (Upper arm module) is connected to the shoulder module by an active rotational shoulder joint. The fifth module (Forearm module) is articulated to the previous module by an active rotation elbow joint. The sixth and the last module (Hand module) is joined with its preceding module by an active rotational wrist joint. Figure 1.2 shows a view of ULEL in which a set of information is about its structure and the positive direction of the activated joints.
Fig.1.1. Upper Limb Exoskeleton of LISSI (ULEL)Fig.1.2. Mechanical structure of ULEL
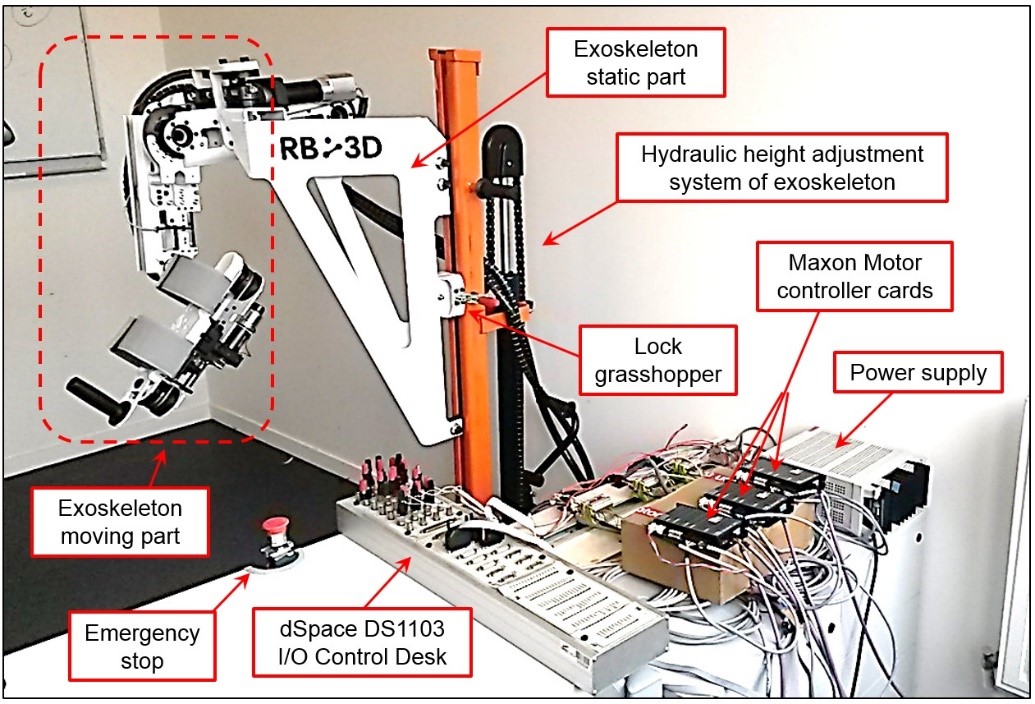
The articulations of shoulder, elbow, and wrist are actuated by powerful DC motors. A power supply and an adequate electrical control system are used to provide regulation for motor currents. An ingenious screw and cable mechanical system is used to apply torques at human joints. The generated torques permit realizing flexion/extension movements of the activated joints. The joint positions are measured by incremental encoders with satisfactory measurement accuracy. The controller is programmed on a PC equipped with a dSpace DS1103 PPC real-time controller card, using Matlab/Simulink and dSpace Control Desk software. For security reasons, the joints are constrained by safety ranges of motion and the electric motor currents are limited. An emergency stop system can be easily activated in the case of an alert. Figure 1.3 shows the experimental setup of ULEL.
Deep Learning and Ontology based Probabilistic Reasoning for Recognising Affordances and Intention
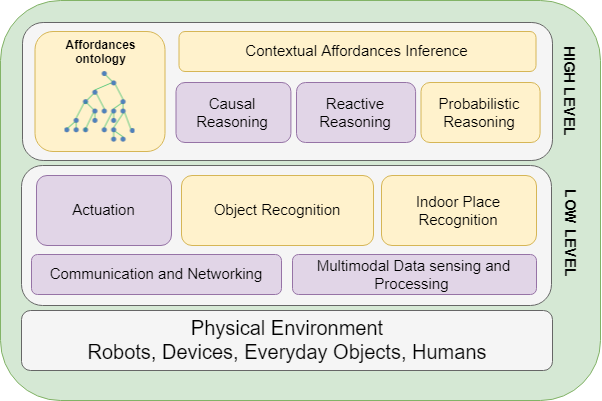
This is a prototype of a smart system that can be implemented in ubiquitous robots to endow them with capability of making online recognition of objects affordances and infer user's intention. In fact visual intelligence is one of the most important aspects of human cognition, and the paramount goal of visual intelligence is the contextual visual reasoning. Take a cup as an example. From a single image, humans can infer its name, texture, color, and what actions the object affords. The smart system uses a semantic knowledge representation model where the notion of contextual object affordance is modeled as the relationship between an object and a set of actions this object allows in a given situation. In other words, objects might afford different actions at different places, times, or situations. The smart system uses contextual object affordances as a means to filter the possible actions that a companion robot can monitor/do in an ambient assisted living environment. Besides, contextual affordances can be used as part of a bigger process to extract an agent’s (humans or robots) intentions, by restricting the possible intentions based on the affordable actions in the environment in a given time.
The architecture of the smart system is composed of modules that can predict the contextual object affordances based on place information, can make classification and semantic reasoning for inferring the user's intention, thanks to the combination of Deep Convolutional Networks (CNNs) and Probabilistic Description Logics (DL). The role of the probabilistic DL reasoning is to provide the ability to produce contextual affordances based on low-level object and place information.
This prototype developed in the Emospaces european project is still under tests and a video demo will be made available soon.
References:
H. Abdelkawy, S. Fiorini, A. Chibani, N. Ayari, and Y. Amirat, "Deep CNN and Probabilistic DL Reasoning for Contextual Affordances," in Proc. of the AAAI 2018 Fall Symposium Series, Arlington, United States, Oct. 2018. .
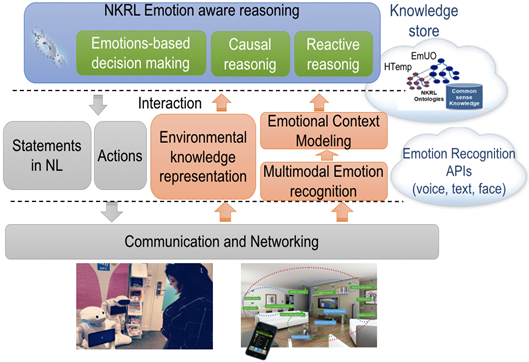
This demo presents a prototype of a smart system that can be implemented in ubiquitous robots to endow them with capability of making online multimodal emotion recognition and taking into account the context of that. The context includes relevant attributes such as Human’s eye gaze, brows, lips, and face muscles motions and positions, which can be used as good features for recognising the facial expression. In addition, focusing on words used, their syntactic structure, their meaning, and the manner with which they are produced via the intensity and quality of the voice appears as a good features vector for recognising emotions on speech. As emotion is defined as an immediate reaction following an event, it is important to take into account what is happening around the human. In this work, speech and audio-visual modalities are taken into account for the expressiveness of the information that they contain. This contextual information are relevant to the multimodal emotion recognition at the low level. Many features influence the emotional meaning. In this work, three features are extracted from audio-visual data such as age, gender, and culture that are considered as a vector of "emotion analysis" features. These latter improve emotion recognition.
Figure 1: Cognitive architecture for designing emotion-aware ubiquitous robots
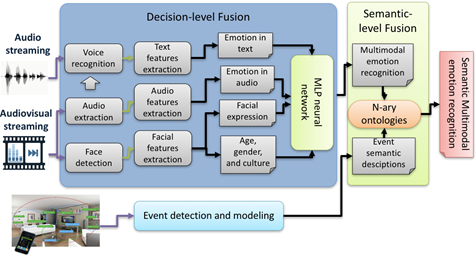
To endow ubiquitous robots with sufficient cognitive capabilities to do an accurate emotion recognition, an hybrid reasoning model for emotion recognition is proposed in this work. This model is based on hybrid fusion techniques that combine information of multiple modalities at different levels. In this paper, hybrid fusion consists of combining, at the low level, features with decisions fusion techniques based on MLP neural network. At the high level, the result of these techniques is exploited by the proposed semantic representation and reasoning models based on NKRL. The architecture of the proposed multimodal emotion recognition system is shown in the following figure.
Figure 2: hybrid reasoning model for emotion recognition
References:
N. Ayari, H. Abdelkawy, A. Chibani, and Y. Amirat, "Towards Semantic Multimodal Emotion Recognition for Enhancing Assistive Services in Ubiquitous Robotics," in Proc. Of the AAAI 2017 Fall Symposium Series, Arlington, United States, Nov. 2017, pp. 2-9.
Semantic Reasoning for Natural and Seamless interactions between robots, humans and smart objects
In this case, we present a scenario, where assistive agents can collectively work together to solve ubiquitous problems. This scenario captures the milk dilemma and a possible solution where machines and sensors can assist in answering this daily issue. Let us consider when Eden goes to the grocery store, do she always remember to capture all the required food before departing. The answer is commonly, ”no”, as humans often forget to check many common items. For example, while at the store she don’t know the amount of milk available at home, a call can typically be made to someone at home (Steve) to query the status of milk. If there is no human at home to call the problem then falls to another actor in the system to answer the common query. Why not ask the refrigerator or the companion robot to determine this status? In this case, the task of determining the milk status is indistinguishable between another human, a robot or any other machine like the refrigerator. Which system actor answers the query of the milk status does not matter. The key point is the adequate capability present to answer the query.
In this scenario, let us assume that reasoning system of the refrigerator will notify the companion robot each time when a food (milk) is missing or if it becomes bad. When Eden approaches a grocery store, her smart phone will recognize the proximity to the grocery store an notifies the smart objects at home. The robot and the refrigerator will capture this notification and only the robot has the reasoning capability for dealing with that. It will decide to contact Eden asking her to buy the milk. We consider that Eden will accept and may ask if is there some yogurt. When the refrigerator and the robot reasoners fail in providing an answer by querying their local knowledge bases, the robot decides to ask the closest person “Steve” to get the missing information and forward the answer to Eden. Semantic reasoning, natural interactions and context awareness are the key concepts that makes the intelligence of actors. To further this innovation, the relationship between Humans, software Agents, Robots, Machines and Sensors (HARMS) must approach that of indistinguishability in multi agents systems communication. In fact, the whole concept of indistinguishability is novel and useful in terms of capability based organizations, where the system selects a task for execution, based on the capability of some agent (or other HARMS actor) given its capability to accomplish the selected task or solve a goal. All available actors with that specific capability allow the choice to be indistinguishable. Communication is the medium to enable indistinguishability, but is useful in an organization setting where group rational decisions and choices are made
References:
N. Ayari, A. Chibani, Y. Amirat, and E. Matson, "A Semantic Approach for Enhancing Assistive Services in ubiquitous robotics," Robotics and Autonomous Systems, Elsevier, vol. 75, pp. 17-27, 2016. .
A. Chibani, A. Bikakis, T. Patkos, Y. Amirat, S. Bouznad, N. Ayari, and L. Sabri, "Using Cognitive Ubiquitous Robots for Assisting Dependent People in Smart Spaces," in Intelligent Assistive Robots- Recent advances in assistive robotics for everyday activities, S. Mohammed and J. C. Moreno and K. Kong and Y. Amirat Eds, Springer Tracts on Advanced Robotics (STAR) series, 2015, pp. 297-316. .
N. Ayari, A. Chibani, and Y. Amirat, "Semantic Management of Human-Robot Interaction In Ambient Intelligence using N-ary ontologies," in ICRA 2013, Karlsruhe, Germany, May. 2013, pp. 1164-1171. .
N. Ayari, A. Chibani, and Y. Amirat, "A Semantic Approach to Enhance Human-Robot Interaction in AmI Environments," in Human-Agent Interaction, Workshop at IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2012, Vilamoura, Portugal, 2012. .
Ubiquitous robots play a significant role in fostering traditional ambient and assisted living. For instance, companion robots can accurately and closely monitor humans daily activities and wellbeing thanks to their ability of autonomously moving, sensing the environment, recognizing and tracking features of interest, making different sorts of reasoning tasks and triggering context aware reactive actions. In this scenario we demonstrate the feasibility of a cognitive component for context aware monitoring based on ontologies and inference rules according to the close world assumption reasoning. Context awareness can be defined as the capacity of a cognitive entity to measure, detect and infer a set of contextual features that are identifiable in time and space. Let us consider the case where Nathan, who have a kind of hypotension issues, goes directly to the gymnasium Kitchen after finishing his football game, to drink some water. Sort time after opening the tap and drinking a glass of water, he suddenly fall down shortly. Current monitoring system do/cannot detect such event when they happen and usually persons do not trigger alarms. The robot, which is able to make semantic correlations and production inferences, can move and recognize the context and decide to trigger an alarm in the case of real emergency. In this scenario we show how the design of inference rules is made separately whiteout considering the effective description of the real world sensors and actuators. The reasoning core of the system can make autonomously the semantic mapping between the raw data sent by the wireless sensors and the ontology and inference rules is done under a Closed-World Assumption (CWA), which means that all statements that have not been mentioned explicitly to be true are necessarily false. In contrast the OWL based reasoning that uses an Open-World Assumption (OWA), when the reasoner is asked on the truth value of a missing information it does not provide any response and the query/rule is simply ignored.
References:
L. Sabri, S. Bouznad, S. Fiorini, A. Chibani, E. Prestes, and Y. Amirat, "An integrated semantic framework for designing context-aware Internet of Robotic Things systems," Integrated Computer-Aided Engineering, IOS Press, vol. 25, no. 2, pp. 137-156, 2018. .
S. Bouznad, A. Chibani, Y. Amirat, L. Sabri, E. Prestes, F. Sebbak, and S. Fiorini, "Context-Aware Monitoring Agents for Ambient Assisted Living Applications," in Proc. Of the 13th European Conference on Ambient Intelligence, AmI 2017, Malaga, Spain, 2017, pp. 225-240. .
A. Chibani, A. Bikakis, T. Patkos, Y. Amirat, S. Bouznad, N. Ayari, and L. Sabri, "Using Cognitive Ubiquitous Robots for Assisting Dependent People in Smart Spaces," in Intelligent Assistive Robots- Recent advances in assistive robotics for everyday activities, S. Mohammed and J. C. Moreno and K. Kong and Y. Amirat Eds, Springer Tracts on Advanced Robotics (STAR) series, 2015, pp. 297-316. .
L. Sabri, A. Chibani, Y. Amirat, G. P. Zarri, and P. Gatellier, "Semantic framework for context-aware monitoring of AAL ecosystems," in Ambient Assisted Living, N. M. Garcia and J. Rodrigues and D. C. Elias and M. S. Dias and Eds. Eds, Taylor and Francis / CRC Press, 2015, pp. 573-602. .
Reasoning on Conflicting situations for Ambient Assisted Living
The execution of temporal projection tasks represents a popular formal technique in the field of cognitive robotics, while its practical significance is also evidenced in recent implementations of autonomous systems. Its use in AmI domains can provide an extra leverage in achieving proactive behavior. The following example demonstrates a case that has been modeled in Event calculus and implemented and experimented in the living lab. Imagine that the inhabitant, while being at the kitchen, turns on the Kettle, Oven or hot plate and places a pot containing milk. The content of the pot will begin to heat up and eventually start to boil. There is no dedicated sensor measuring the temperature of the milk; we rely on commonsense derivations in order to model this behavior. As such, the system can also expect that the boiling point will be reached after a while, and therefore sets a timer to become aware of this incident. The objective of the monitoring system is to identify potentially conflicting situations both at the present time and in the future, in order to trigger different types of alerts and recommendations in an as less intrusive manner as possible. In this case, by performing temporal projection with a time window of more than 3 minutes the system will predict that the milk will start to boil; yet, since the user can reasonably be assumed to be in the kitchen, no preventive action needs to be taken and any alert can be postponed until a later point.
Returning in real-time mode, imagine that the inhabitant then leaves the kitchen, enters the bathroom and turns on the bathtub faucet causing water to start filling the bathtub. A progression of the world state now will allow the system to identify that the two parallel activities of milk heating up and water filling the bathtub will demand the user’s attention at approximately the same time at two different locations: he should stop the water from reaching the rim of the bathtub while also turn off the hot plate in the kitchen. Although the critical situation refers to a future point in time and it is not certain that it will actually occur, a warning message is more appropriate to be placed in the present state. The reasoning system will infer on the following: move the robot to the inhabitant current location and initiate an audio message to warn him about the situation and suggest him to turn off the kettle, the oven or the hot plate. In different cases, the reasoning system may instead decide to take initiative, such as to turn off the appliance on the inhabitant's behalf.
References:
T. Patkos, D. Plexousakis, A. Chibani, and Y. Amirat, "An Event Calculus production rule system in dynamic and uncertain domains," Journal of Theory and Practice of Logic Programming, Cambridge University Press, vol. 16, no. 3, pp. 325-352, 2016. .
A. Chibani, A. Bikakis, T. Patkos, Y. Amirat, S. Bouznad, N. Ayari, and L. Sabri, "Using Cognitive Ubiquitous Robots for Assisting Dependent People in Smart Spaces," in Intelligent Assistive Robots- Recent advances in assistive robotics for everyday activities, S. Mohammed and J. C. Moreno and K. Kong and Y. Amirat Eds, Springer Tracts on Advanced Robotics (STAR) series, 2015, pp. 297-316. .
T. Patkos, A. Chibani, D. Plexousakis, and Y. Amirat, "A Production Rule-based Framework for Causal and Epistemic Reasoning," in Proc. Of the RuleML Symposium held in conjunction with ECAI 2012, the 20th biennial European Conference on Artificial Intelligence, Montpellier, France, 2012, pp. 120-135. .
B. Hu, T. Patkos, A. Chibani, and Y. Amirat, "Rule-Based Context Assessment in Smart Cities," in Proc. Of the 6th International Conference on Web Reasoning and Rule Systems, RR 2012, Vienna, Austria, 2012, pp. 221-224. .
B. Hu, A. Chibani, and Y. Amirat, "Semantic context relevance assessment in urban ubiquitous environments," in Proc. Of the 14th International conference on Ubiquitous Computing UbiComp'12, Pittsburgh, United States, 2012, pp. 639-640. .
Dataset for Recognition and Reasoning on Activities of Daily Living
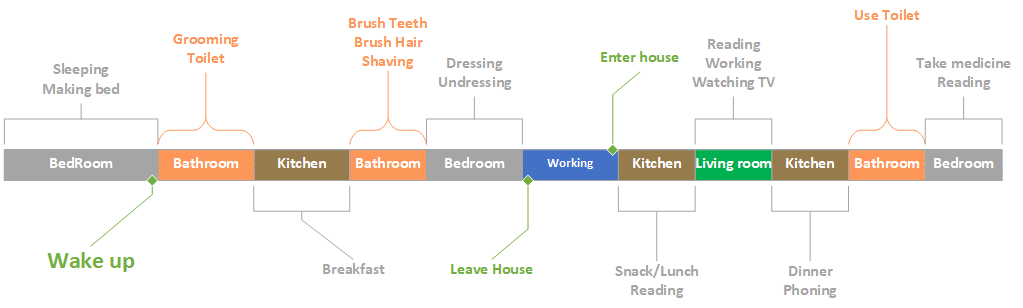
This dataset was collected as part of the research activity of the SIRIUS team on human activity recognition and behaviour analysis to implement context aware ambient assisted living robotic systems. This dataset is composed of replay of the most common activities of the daily living that can occur in a typical day at the main rooms of any apartment. The dataset is used for developing new methodologies for machine learning and reasoning in order to enable any agent with the capability to recognize automatically the activity that can happen in normal contexts as well activities that can happen in abnormal contexts, which may be just exceptional with no criticality or dangerous to human to safety.
Fig.1. Typical daily living activity of the dataset
The activities that can happen in abnormal contexts, which reflects the situation that may face most of the elderly persons living independently. These situations are considered as anomalies in the context of an activity which can happen from time to time in the course of the daily life of an elderly. Detecting the abnormal context, will enable an assistive agent to prevent that these contexts happens or react in order to protect the elderly inhabitant. In this dataset, are considered two kinds of abnormal contexts: (i) Memory leak that corresponds to forgetting a mandatory action such as forgetting to remove the pan from the hotplate after eating or Forgetting the drugs). (ii) Executing activities in non-suitable temporal and spatial context such as preparing breakfast instead of dinner (after a nap and after a snack) or sleeping just after waking up, do not take necessary time to take the meal.
To ensure a maximum of realism in the daily activities, the experimental protocol takes into account the following scenarios:
• Interleaved activities (C): an activity B begins before the end of the previous activity A without stopping or interrupting it, the latter ending before the end of activity B.
• Interrupted activities (I): an activity B begins in the middle of the progress of another activity A, when the faith is over, the subject resumes the interrupted activity, A.
• Sequenced activities (S): sequential activities, one after the other, without one of them interrupting the other.
• Concurrent activities (P): Two activities, A and B, start at the same time and are performed independently of each other.
The dataset collection environment is setup in the LISSI laboratory premises. It is composed of four main spaces corresponding to a bedroom (Figure 2.A), bathroom (Figure 2.B), living room (Figure 2.C) and kitchen (Figure 2.D). In these spaces, we have deployed the wireless sensors and software systems of the ubistruct platform that are necessary to capture the daily living activities ( see http://www.plateforme-ubistruct). The deployed infrastructure is running with standard IoT protocol such as Bluetooth, Wifi, 6lowpan and Zigbee. The sensors are synchronized over the internet and transmit the sensed data online by using the XMPP and HTTP (REST) protocols.
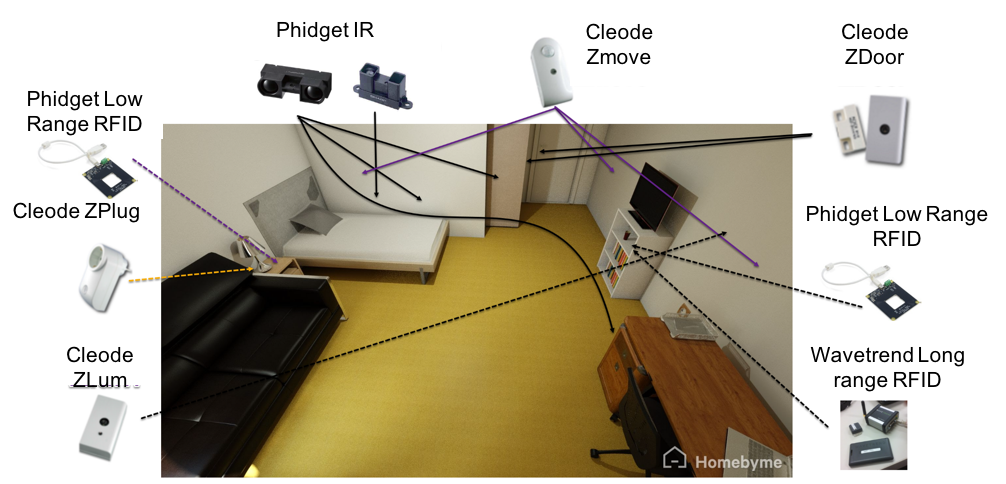
The bedroom has a surface of 12 m², it contains basic furniture that we can find any bedroom such as a bed, a night table, a night light, a closet and a shelf as well as desk. This room also has a curtained window. In this dataset, the high-level activities are limited to sleeping, changing clothes, making the bed, drinking water, taking drugs, reading a book and making calls with the phone. The low-level activities are: Open/closing the curtains/window/door/cupboard, switching on/off the spot-light, lying, walking, getting up and sitting.
Fig.2.A. Bedroom Instrumentation
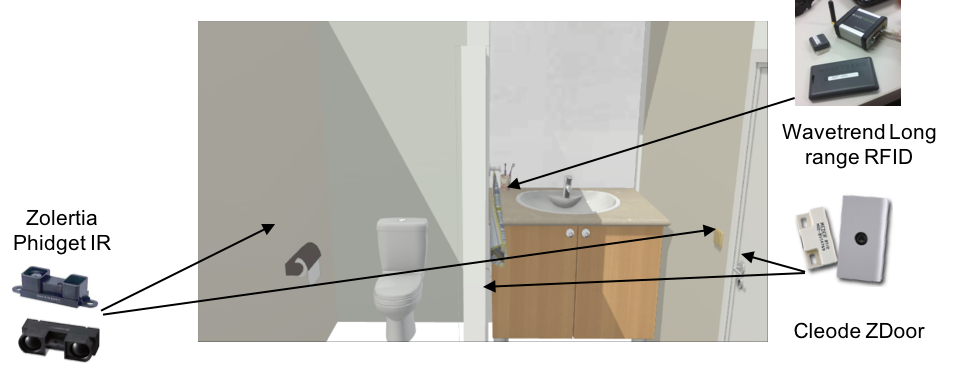
The bathroom is composed of two sub-spaces; toilet and cleaning. The inhabitant is supposed to do a variety of high level activities in both sub-spaces of the bathroom freely and without any predefined scenario. The bathroom cleaning sub-space is mainly used for washing the face and the hands that can happen at any time of the day, but also for brushing hair, shaving brushing teeth, which are common to happen before sleeping or after waking up. The low-level activities are open/close the door, flush the toilet, Open/Close the tap, Take or Pose an object, etc.
Fig.2.B. Bathroom Instrumentation
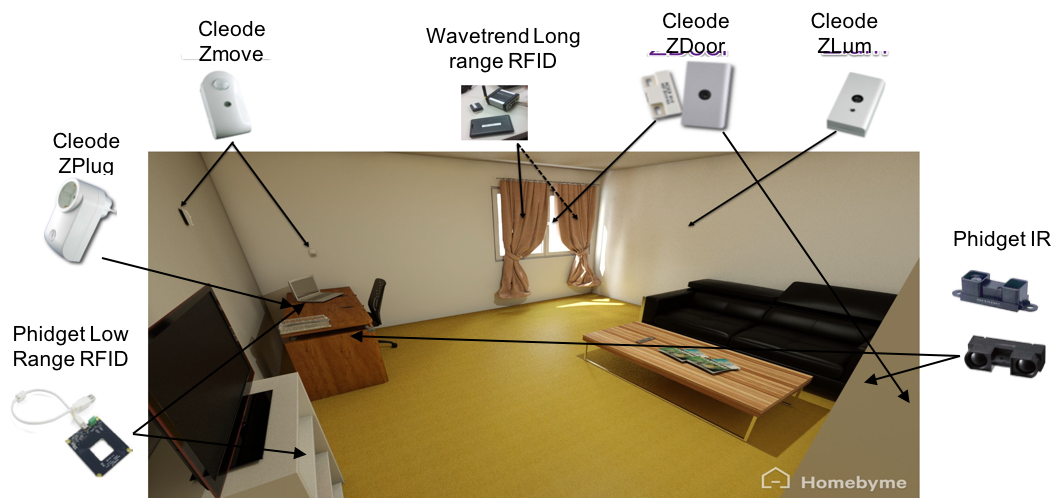
The living room space is a rearrangement of the bedroom space, which has a surface of 12 m². Two level of activities are considered in this context. The high-level activities are (i) relaxing and leisure activities such as watching television, reading a book, etc (ii) social activities such as speaking to friends with mobile phone or social apps, (iii) receiving guests and also working from time to time. Eating in the living room is an exceptional activity. Therefore, only taking a snack is considered in this experiment. The corresponding low-level activities corresponds to following actions: waking, lying on the sofa, Sitting on chair, getting up, Open/close the curtains/doors/windows, use the remote control of the television, etc.
Fig.2.C. Livingroom Instrumentation
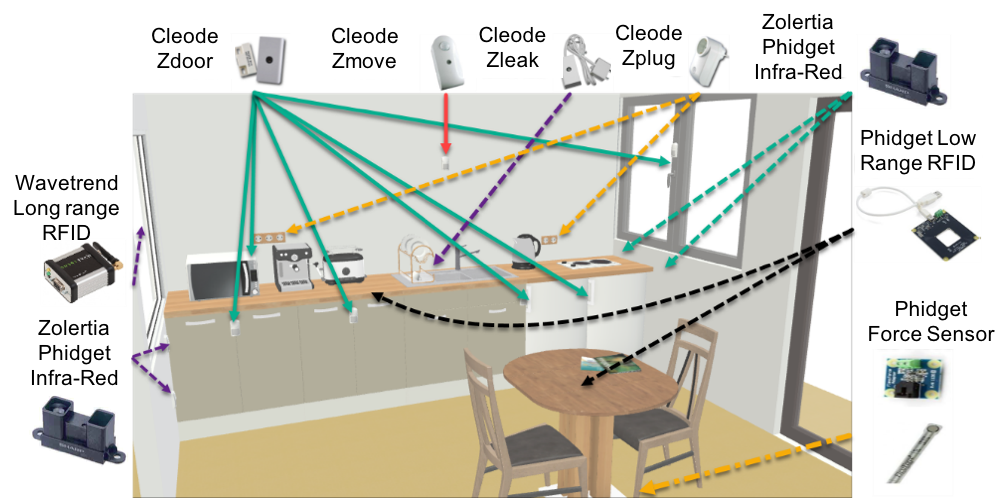
The kitchen space contains more or less the same sensors, except the force sensors that are used to capture, which is the chair that is used by the inhabitant. The high-level activities captured in this space are cooking, cleaning and taking meals and medications. The cooking activity for each day includes several mid-level activities from the following list: prepare the milk, prepare cereal, prepare a salad, prepare an accompaniment of the main course, prepare a fruit soft drink, prepare a coffee, Prepare tea, Heat a meal already prepared, take the drugs, etc.
Fig.2.D. Kitchen Instrumentation
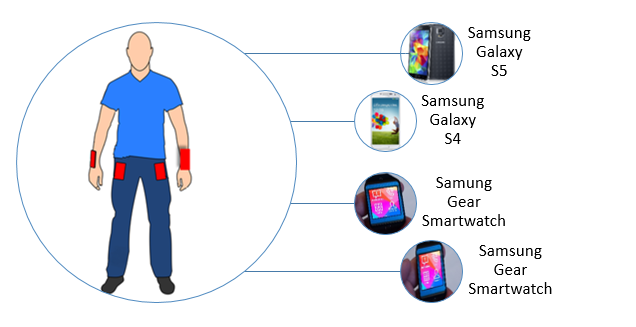
To capture human motions and physical actions, the inhabitant must wear during the experiments two smart-watches and two smart phones, see figure 3. The latter are used to assure the continuous acquisition of the 3D acceleration data from embedded sensors of these wearable devices.
Fig.3. Wearable Sensors
To ensure richness of data-set, each subject must repeat a series of actions several times. These actions compose the different high-level activities such. The considered actions are: Open/closing the doors of rooms, the windows and also the doors of the furniture’s, pouring the drink into a glass, stir a liquid with a tea spoon, Mix ingredients in a dish, etc.
Hybrid orthosis/FES assistance of knee joint flexion/extension movements
This demonstrator describes a cooperative control approach that combines the use of a powered knee joint orthosis along with Functional Electrical Stimulation (FES) for knee joint flexion extension movement restoration. A closed-loop adaptive control and an open-loop FES of the quadriceps muscle group are combined together to track a desired knee joint angle trajectory of flexion/extension movements. A nonlinear disturbance observer is used to estimate the torque provided by the subject’s muscles through the FES. Preliminary experiments with a healthy subject show the feasibility of the proposed approach. Experiments show the repeatability of motion and the complementarity between the torque provided by the quadriceps muscle through FES and the one delivered by the orthosis actuator to ensure satisfactory tracking of the desired trajectory.
References:
[1] M.-A. Alouane, H. Rifai, Y. Amirat and S. Mohammed, “Cooperative Control for Knee Joint Flexion-Extension Movement Restoration", IEEE/RSJ IROS 2018, Accepted
Human-Exoskeleton System Dynamics Identification Using Affordable Sensors
This demonstrator shows a practical method to identify body segments inertial parameters of a human-exoskeleton system using affordable and easy-to-use sensors. First, the joints and the base kinematics are estimated based on the use of an extended Kalman filter and QR visual markers. Then, joints kinematics are used in a dynamic identification pipeline together with the ground reaction force and moments collected with an affordable Wii Balance Board. The identification process is done using an augmented regressor matrix to identify at once each segment mass, center of mass 3D position and inertia tensor elements of both human locomotor apparatus and exoskeleton. The proposed method is able to accurately estimate external force and moments with less than 6% of normalized RMS error in average and is experimentally validated with a subject wearing a full lower-limb exoskeleton as it is shown in the below video.
Squat motions performed with and without the exoskeleton
References:
[1] R Mallat, V Bonnet, W Huo, P Karasinski, Y Amirat, M. Khalil and S Mohammed, “Human-Exoskeleton System Dynamics Identification Using Affordable Sensors", Proc. Of the IEEE International Conference on Robotics and Automation, ICRA 2018
[2] R. Mallat, V. Bonnet, M. Khalil, S. Mohammed, “Dynamic identification of a human-exoskeleton-system”, in Proc. Of the 4th IEEE International Conference on Advances in Biomedical Engineering, ICABME 2017, Beirut, Lebanon, 19-21 Oct. 2017, pp. 1-4.
Adaptive Functional Electrical Stimulation to assist Foot-Drop paretic patients
This demonstrator shows an adaptive knee-joint based Functional Electrical Stimulation (FES) method to correct the foot drop of paretic patients during swing phase. The rationale behind adaptive FES is to amplify dorsiflexor stimulation in the late swing when it is most needed in order to face the increased plantar flexor co-contraction as gastrocnemius muscles are stretched by knee re-extension. To accurately detect the swing phase (i.e., toes off (TO) and initial contact (IC)), a novel algorithm is proposed by using a foot-mounted inertial measurement unit (IMU). The proposed strategy is verified by experiments conducted with three healthy subjects and three paretic patients. The experimental results show that highly accurate detection of TO/IC can be achieved under different walking speeds and foot contact conditions (normal and abnormal gaits). The clinical experimental results with paretic patients also revealed that similar effects on ankle dorsiflexion can be observed during mid and late swing using the proposed adaptive FES with respect to the standard FES ON/OFF method, while the adaptive FES used lower stimulation intensity.
References:
[1] W. Huo, V. Arnez-Paniagua, M. Ghedira, Y. Amirat, J-M Gracies, and S. Mohammed, “Adaptive FES Assistance using a Novel Gait Phase Detection Approach", IEEE/RSJ IROS 2018, Accepted
[2] W. Huo, M. Ghedira, S. Mohammed, V. Arnez-Paniagua, E. Hutin, J-M Gracies,
"Effect of knee joint angle-based, adaptive functional electrical stimulation of the peroneal nerve in spastic paresis. A case report", Annals of Physical and Rehabilitation Medicine, 61, e475-e476, 2018